語音辨識
語音辨識技術提供語音轉文字(音轉字)功能,在生活中常見的SIRI、手機/電腦上的語音輸入法及智慧音箱等應用都可看見音轉字的身影,而在實際使用音轉字時,可能會受環境噪音干擾,此時需要靠端點偵測及語音增強等技術來維持辨識準確度,並且介紹跟語音辨識相關的技術,如:智慧音箱上的喚醒語偵測、掌握語音中每段聲音是誰在說話的語者分段,最後提供國、台、客語音轉字線上體驗。
端點偵測(Endpoint Detection)
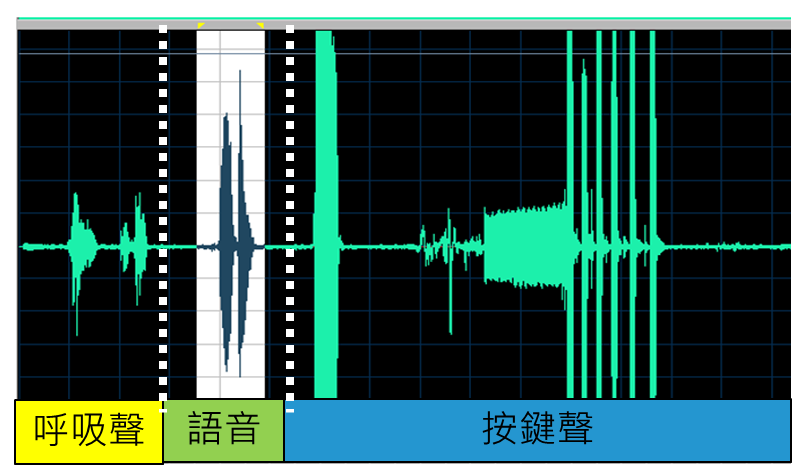
端點偵測(Endpoint Detection)的目標是要決定語音開始和結束的位置,又可以稱為 Speech Detection 或是 VAD (Voice Activity Detection)。VAD在音訊處理與辨識中,可過濾掉非語音的訊號,改善語音辨識率。
喚醒語偵測(Wake Word Detection)
在使用智慧音箱的情境下,在進行語音互動前,音箱需要先被喚醒,從休眠狀態進入工作狀態,才能正常的處理使用者的指令。把音箱從休眠狀態叫醒到工作狀態所使用到的技術即為喚醒語偵測。
語音增強(Speech Enhancement)
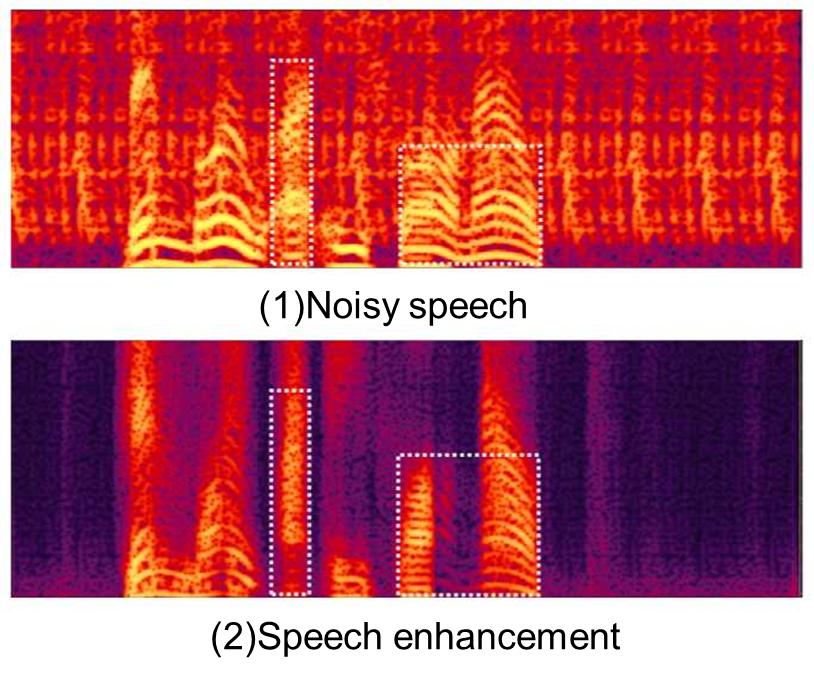
語音增強(Speech Enhancement)是指當語音訊號被各式各樣的噪音干擾,從噪音背景中提取有用的語音訊號,是一種抑制及降低噪音干擾的技術,簡言之,從有噪音的語音中提取盡可能乾淨的語音。
語者分段(Speaker Diarization)
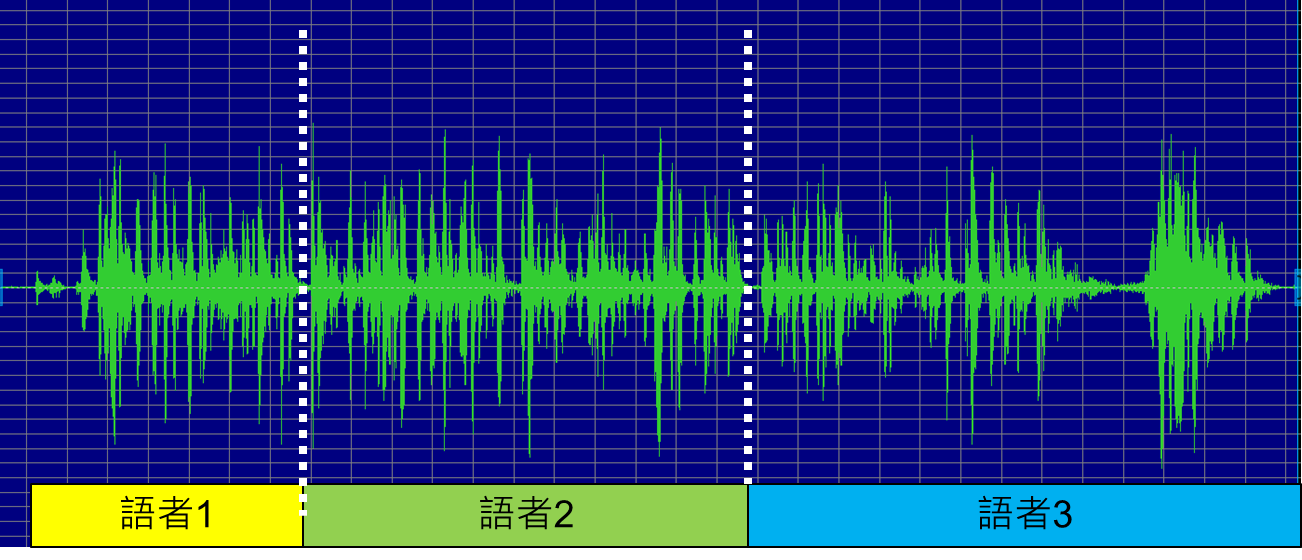
語者分段(Speaker Diarization)可以從一段語音中,識別出是誰在説話,其又説了些什麽。
由於每個人的聲學特徵不一樣,根據聲學信息,我們就能將分散的語音訊號進行聚類(Clustering),一名説話者對應至一類,從而標註出每一個片段的説話者。
音轉字(Speech to Text)
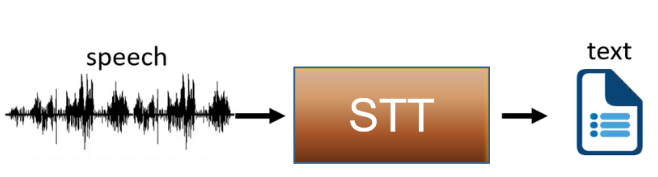
音轉字(Speech to Text, STT)其目的是自動將人類的語音內容轉換為相應的文字,俗稱逐字稿,而且還會在逐字稿中自動加上標點符號。
台語STT展示:
客語STT展示:
語音辨識
語音辨識技術提供語音轉文字(音轉字)功能,在生活中常見的SIRI、手機/電腦上的語音輸入法及智慧音箱等應用都可看見音轉字的身影,而在實際使用音轉字時,可能會受環境噪音干擾,此時需要靠端點偵測及語音增強等技術來維持辨識準確度,並且介紹跟語音辨識相關的技術,如:智慧音箱上的喚醒語偵測、掌握語音中每段聲音是誰在說話的語者分段,最後提供國、台、客語音轉字線上體驗。
端點偵測(Endpoint Detection)
端點偵測(Endpoint Detection)的目標是要決定語音開始和結束的位置,又可以稱為 Speech Detection 或是 VAD (Voice Activity Detection)。VAD在音訊處理與辨識中,可過濾掉非語音的訊號,改善語音辨識率。
喚醒語偵測(Wake Word Detection)
在使用智慧音箱的情境下,在進行語音互動前,音箱需要先被喚醒,從休眠狀態進入工作狀態,才能正常的處理使用者的指令。把音箱從休眠狀態叫醒到工作狀態所使用到的技術即為喚醒語偵測。
語音增強(Speech Enhancement)
語音增強(Speech Enhancement)是指當語音訊號被各式各樣的噪音干擾,從噪音背景中提取有用的語音訊號,是一種抑制及降低噪音干擾的技術,簡言之,從有噪音的語音中提取盡可能乾淨的語音。
語者分段(Speaker Diarization)
語者分段(Speaker Diarization)可以從一段語音中,識別出是誰在説話,其又説了些什麽。
由於每個人的聲學特徵不一樣,根據聲學信息,我們就能將分散的語音訊號進行聚類(Clustering),一名説話者對應至一類,從而標註出每一個片段的説話者。
音轉字(Speech to Text)
音轉字(Speech to Text, STT)其目的是自動將人類的語音內容轉換為相應的文字,俗稱逐字稿,而且還會在逐字稿中自動加上標點符號。
台語STT展示:
客語STT展示: